Make Encoder Great Again in 3D GAN Inversion through Geometry and Occlusion-Aware Encoding
Ziyang Yuan*,Yiming Zhu*, Yu Li, Hongyu Liu, Chun Yuan ICCV2023
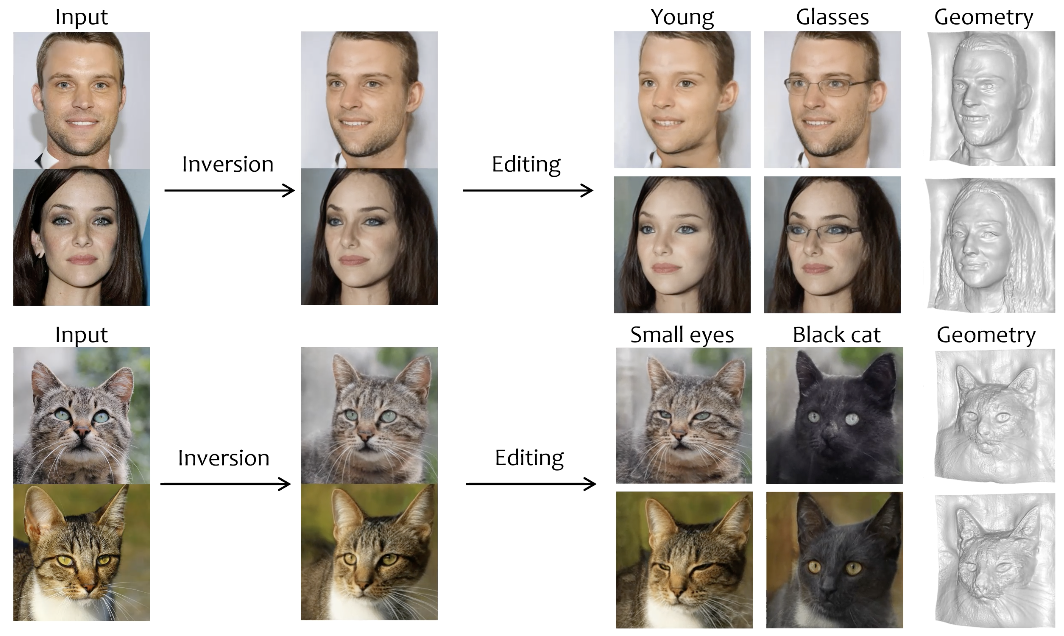
3D GAN inversion aims to achieve high reconstruction fidelity and reasonable 3D geometry simultaneously from a single image input. However, existing 3D GAN inversion methods rely on time-consuming optimization for each individual case. In this work, we introduce a novel encoder-based inversion framework based on EG3D, one of the most widely-used 3D GAN models. We leverage the inherent properties of EG3D’s latent space to design a discriminator and a background depth regularization. This enables us to train a geometry-aware encoder capable of converting the input image into corresponding latent code. Additionally, we explore the feature space of EG3D and develop an adaptive refinement stage that improves the representation ability of features in EG3D to enhance the recovery of fine-grained textural details. Finally, we propose an occlusion-aware fusion operation to prevent distortion in unobserved regions. Our method achieves impressive results comparable to optimization-based methods while operating up to 500 times faster. Our framework is well-suited for applications such as semantic editing.
One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations
Yiming Zhu, Hongyu Liu, Yibing Song, Ziyang Yuan, Xintong Han, Chun Yuan, Qifeng Chen, and Jue Wang Advances in Neural Information Processing Systems NeurIPS 2022 (Spotlight)
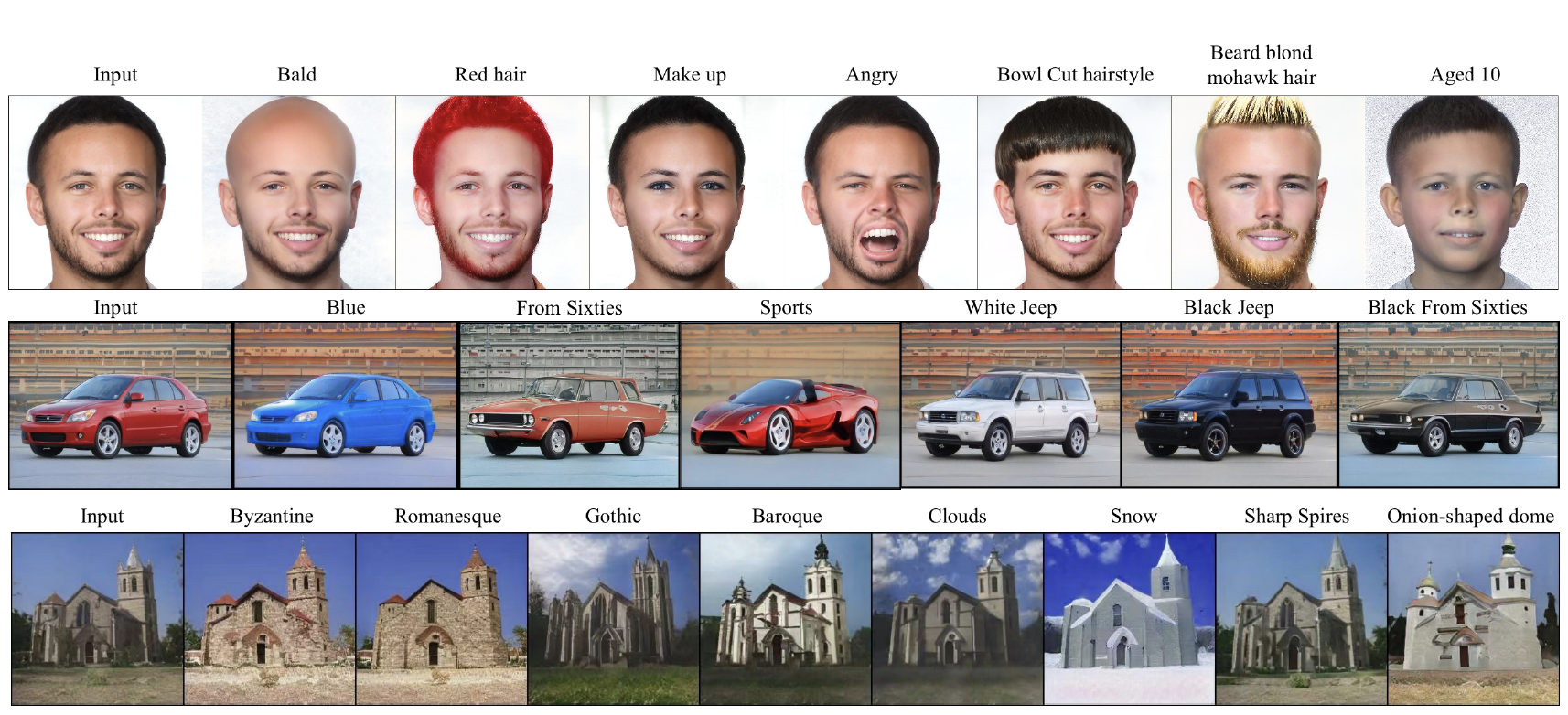
Free-form text prompts allow users to describe their intentions during image manipulation conveniently. Based on the visual latent space of StyleGAN[21] and text embedding space of CLIP[34], studies focus on how to map these two latent spaces for text-driven attribute manipulations. Currently, the latent mapping between these two spaces is empirically designed and confines that each manipulation model can only handle one fixed text prompt. In this paper, we propose a method named Free-Form CLIP (FFCLIP), aiming to establish an automatic latent mapping so that one manipulation model handles free-form text prompts. Our FFCLIP has a cross-modality semantic modulation module containing semantic alignment and injection. The semantic alignment performs the automatic latent mapping via linear transformations with a cross attention mechanism. After alignment, we inject semantics from text prompt embeddings to the StyleGAN latent space. For one type of image (e.g., human portrait), one FFCLIP model can be learned to handle free-form text prompts. Meanwhile, we observe that although each training text prompt only contains a single semantic meaning, FFCLIP can leverage text prompts with multiple semantic meanings for image manipulation. In the experiments, we evaluate FFCLIP on three types of images (i.e., ‘human portraits’, ‘cars’, and ‘churches’). Both visual and numerical results show that FFCLIP effectively produces semantically accurate and visually realistic images.
Diverse Image Inpainting with Normalizing Flow
Cairong Wang* , Yiming Zhu*, Chun Yuan ECCV 2022

Image Inpainting is an ill-posed problem since there are diverse possible counterparts for the missing areas. The challenge of inpainting is to keep the ”corrupted region” content consistent with the background and generate a variety of reasonable texture details. However, existing one-stage methods that directly output the inpainting results have to make a trade-off between diversity and consistency. The two-stage methods as the current trend can circumvent such shortcomings. These methods predict diverse structural priors in the first stage and focus on rich texture details generation in the second stage. However, all two-stage methods require autoregressive models to predict the probability distribution of the structural priors, which significantly limits the inference speed. In addition, their discretization assumption of prior distribution reduces the diversity of the inpainting results. We propose Flow-Fill, a novel two-stage image inpainting framework that utilizes a conditional normalizing flow model to generate diverse structural priors in the first stage. Flow-Fill can directly estimate the joint probability density of the missing regions as a flow-based model without reasoning pixel by pixel. Hence it achieves real-time inference speed and eliminates discretization assumptions. In addition, as a reversible model, Flow-Fill can invert the latent variables for a specified region, which allows us to make the inference process as semantic image editing. Experiments on benchmark datasets validate that Flow-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
DynaMixer: A Vision MLP Architecture with Dynamic Mixing
ZiyuWang, Wenhao Jiang , Yiming Zhu, Li Yuan , Yibing Song , Wei Liu ICML 2022
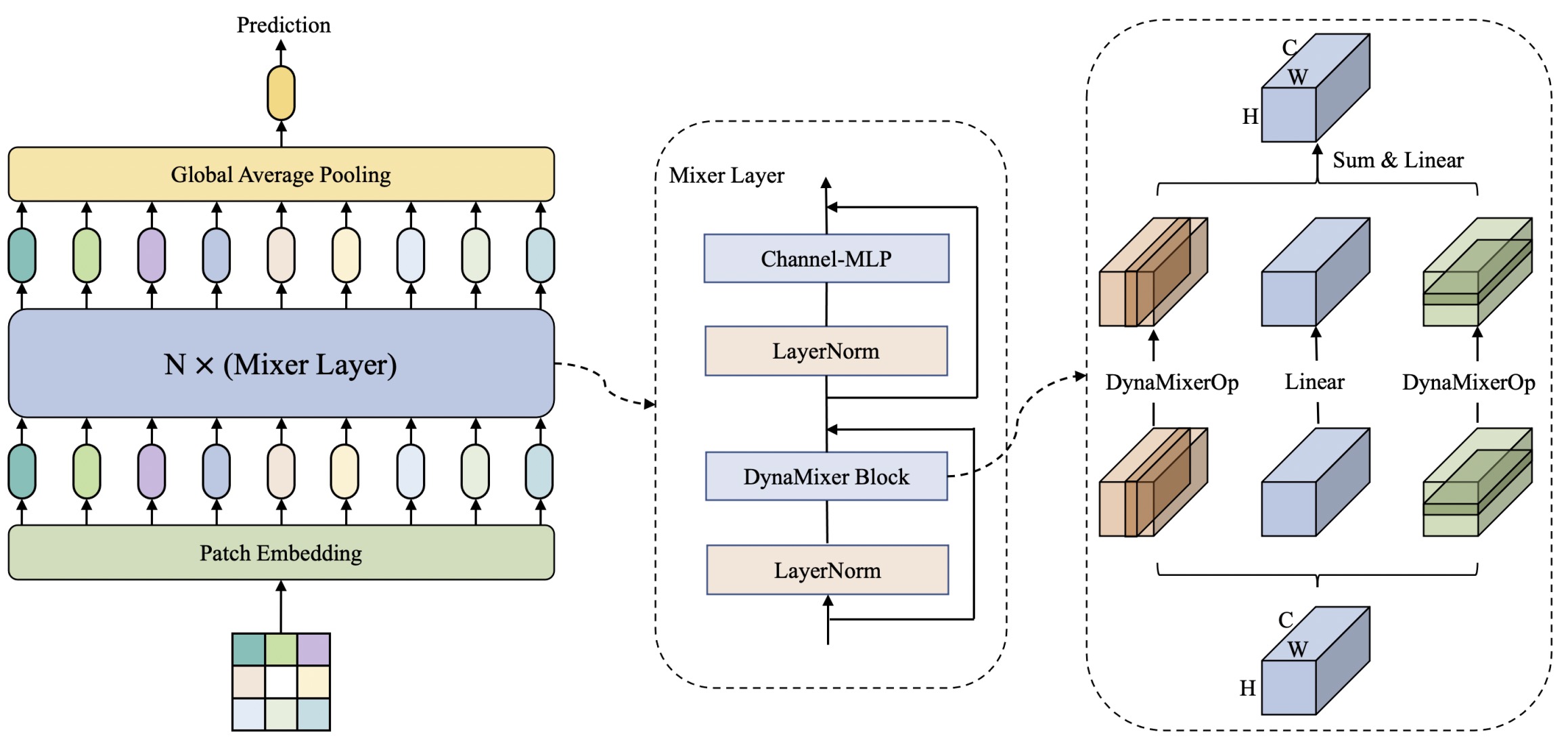
Recently, MLP-like vision models have achieved promising performances on mainstream visual recognition tasks. In contrast with vision transformers and CNNs, the success of MLP-like models shows that simple information fusion operations among tokens and channels can yield a good representation power for deep recognition models. However, existing MLP-like models fuse tokens through static fusion operations, lacking adaptability to the contents of the tokens to be mixed. Thus, customary information fusion procedures are not effective enough. To this end, this paper presents an efficient MLP-like network architecture, dubbed DynaMixer, resorting to dynamic information fusion. Critically, we propose a procedure, on which the DynaMixer model relies, to dynamically generate mixing matrices by leveraging the contents of all the tokens to be mixed. To reduce the time complexity and improve the robustness, a dimensionality reduction technique and a multi-segment fusion mechanism are adopted. Our proposed DynaMixer model (97M parameters) achieves 84.3% top-1 accuracy on the ImageNet-1K dataset without extra training data, performing favorably against the state-of-the-art vision MLP models. When the number of parameters is reduced to 26M, it still achieves 82.7% top-1 accuracy, surpassing the existing MLP-like models with a similar capacity.
High-frequency Normalizing Flow for Image Rescaling
Yiming Zhu, Cairong Wang, Chenyu Dong, Ke Zhang, Hongyang Gao, Chun Yuan TIP
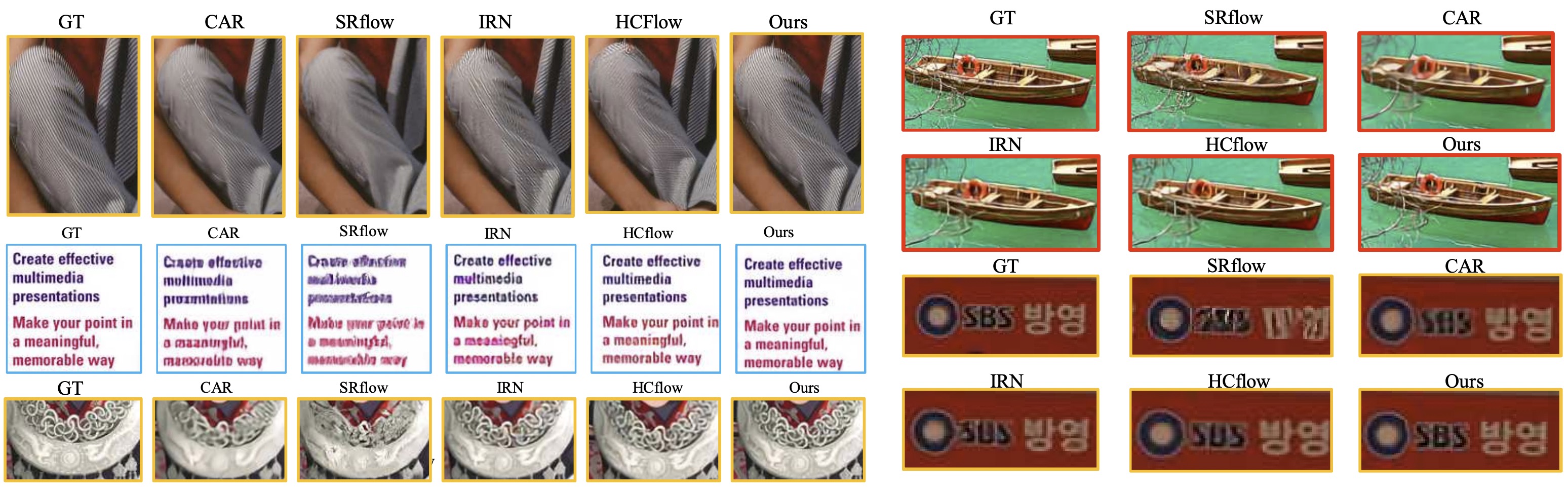
It is desirable to develop efficient image rescaling methods to transmit digital images with different resolutions between devices and assure visual quality. In image downscaling, the inevitable loss of high-frequency information makes the reverse upscaling highly ill-posed. Recent approaches focus on joint learning of image downscaling and upscaling (e.g., rescaling). However, existing methods still fail to recover satisfactory highfrequency signals when upscaling. To solve it, we propose highfrequency flow (HfFlow), which learns the distribution of highfrequency signals during rescaling. HfFlow is an overall invertible framework with a conditional flow on the high-frequency space to compensate for the information lost during downscaling. To facilitate finding the optimal upscaling solution, we introduce a reference low-resolution (LR) manifold and propose a crossentropy Gaussian loss (CGloss) to force the downscaled manifold closer to the reference LR manifold and simultaneously fulfill recovering missing details. HfFlow can be generalized to other scale transformation tasks such as image colorization with its excellent rescaling capacity. Qualitative and quantitative experimental evaluations demonstrate that HfFlow restores rich high-frequency details and outperforms state-of-the-art rescaling methods in PSNR, SSIM, and perceptual quality metrics.
Weakly Supervised Instance Segmentation By Exploring Entire Object Regions
Ke Zhang, Chun Yuan, Yiming Zhu, Yong Jiang, Lishu Luo TMM

Weakly supervised instance segmentation with image-level class supervision is a challenging task as it associates the highest-level instances to the lowest-level appearance. Previous approaches for the task utilize classification networks to obtain rough discriminative parts as seed regions and use distance as a metric to cluster pixels of the same instances. Unlike previous approaches, we provide a novel self-supervised joint learning framework as the basic network and consider the clustering problem as calculating the probability that pixels belong to each instance. To this end, we propose our self-supervised joint learning two-stream network (SJLT Net) to finish this task. In the first stream, we leverage a joint learning framework to implement image-level supervised semantic segmentation with self-supervised saliency detection. In the second stream, we propose a Center Detection Network to detect different instances’ centers with the gaussian loss function to cluster instances pixels. Besides, an integration module is utilized to combine information of both streams and get precise pseudo instances labels. Our approach generates pseudo instance segmentation labels of training images, which are used to train a fully supervised model. Our model achieves excellent performance on the PASCAL VOC 2012 dataset, surpassing the best baseline trained with the same labels by 4.6% 𝐴𝑃𝑟 50 on the train set and 2.6% 𝐴𝑃𝑟 50 on the validation set.